When modeling frequency outcomes, we often need to go beyond the standard Poisson regression due to the strict distributional assumption and to consider more flexible alternatives. In general, there are two broad categories of modeling approaches in light of practical concerns about frequency outcomes.
The first category of models are mainly intended to address the excessive variance, namely over-dispersion, and are including hurdle, zero-inflated Poisson, and latent class Poisson models (https://statcompute.wordpress.com/2012/11/03/another-class-of-risk-models). This class of models assume the mixture of distributions and often require to estimate multiple sets of parameters for different distributions, which might lead to other potential issues, such as variable selection, estimation convergence, or model interpretation. For instance, the hurdle model consists of a logistic regression and a truncated Poisson regression and therefore requires two sets of parameters.
The second category of models are more general to accommodate both over-dispersion and under-dispersion by incorporating complicated variance functions and are including generalized Poisson, double Poisson, hyper-Poisson, and Conway-Maxwell Poisson models (https://statcompute.wordpress.com/2016/11/27/more-about-flexible-frequency-models). This class of models require to simultaneously estimate both mean and variance functions with separate sets of parameters and often suffer from convergence difficulties in the model estimation. All four mentioned above are distributions with two parameters, on which mean and variance functions are jointly determined. Due to the complexity, these models are not even widely used in the industry.
In addition to above-mentioned models with the intention of directly addressing the variance issue, another possibility is to steer away from the problem by using ordinal models. As pointed out by Agresti (2010), “Even when the response variable is interval scale rather than ordered categorical, ordinal models can still be useful. One such case occurs when the response outcome is a count but when standard sampling models for counts, such as the Poisson, do not apply”. An example is that customers with many delinquencies are hardly observable in certain consumer banking portfolios. The similar is also true for insurance customers with a high count of auto claims. In both scenarios, upper limits for frequency outcomes have been enforced by industry practices or corporate policies, putting the application of frequency models in doubt. Additionally, the over-parameterization also makes complicated frequency models less attractive empirically. In such cases, ordinal models, such as Proportional Odds models, are worth considering.
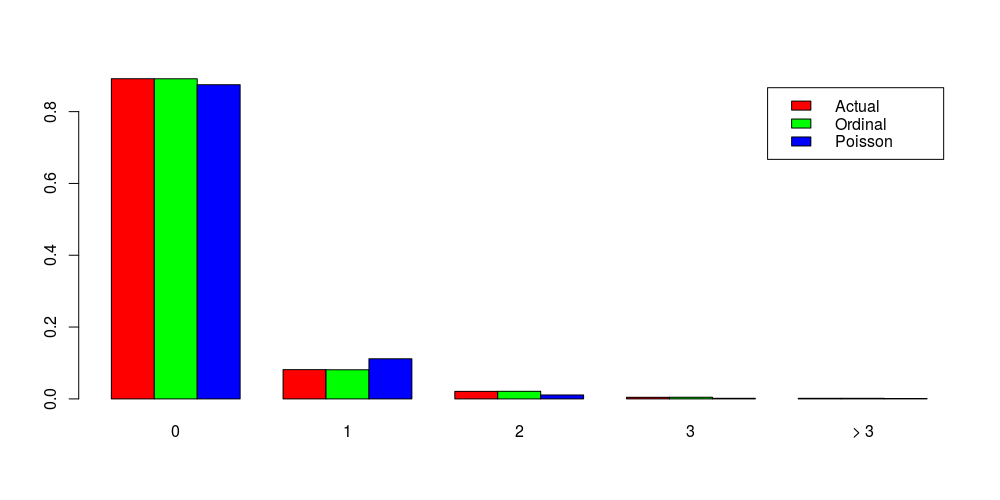
The demonstration below will show how to estimate the frequency of major derogatory reports for credit card customers with a Proportional Odds model. Before the model estimation, it is helpful to examine the distribution of the response variable and shown that nearly 90% cardholders have no major derogatory and the maximum number of incidents is 6, implying that the standard Poisson regression might not be sufficient.
df <- read.csv("Downloads/credit_count.txt")
df1 <- df[which(df$CARDHLDR == 1), ]
freq <- table(df1$MAJORDRG)
# 0 1 2 3 4 5 6
# 9361 855 220 47 13 2 1
Estimating an ordinal model for the frequency outcome is straightforward in R with the rms::orm function. In the model output, different intercepts are used to differentiate different levels of the frequency outcome. Therefore, there are 6 different intercepts in the Proportional Odds model to differentiate 7 levels of derogatory reports from 0 to 6. After the model estimation, we can aggregate the probability of each frequency outcome to derive the conditional distribution of derogatory reports.
Y <- "MAJORDRG"
X <- c("AGE", "ACADMOS", "ADEPCNT", "MINORDRG", "INCPER", "LOGSPEND")
fml <- as.formula(paste(Y, paste(X, collapse = " + "), sep = " ~ "))
m1 <- rms::orm(fml, data = df1, family = logistic)
m1.pred <- data.frame(predict(m1, type = "fitted.ind"))
dist1 <- sapply(m1.pred, sum)
For the comparison purpose, a standard Poisson regression is also estimated with the conditional distribution derived below.
m2 <- glm(fml, data = df1, family = poisson(link = "log")) m2.pred <- predict(m2, type = "response") dist2 <- apply(sapply(0:6, function(i) dpois(i, m2.pred)), 2, sum)
At last, we would compare the observed distribution with conditional distributions from two different models. From the distributional comparison, it is clear that the Proportional Odds model does a better job than the standard Poisson model. (Since the code can not be displayed correctly, I saved it as the image.)


You must be logged in to post a comment.